I never used LangChain
The first commit on the Chain project was May 29, 2024. The very first file, Chain.py, opened with a docstring that read:
This is me running my own framework, called Chain.
A link is an object that takes the following:
- a prompt (a jinja2 template)
- a model (a string)
- an output (a dictionary)
No LangChain anywhere in the repo. I hadn’t migrated from it or built against it. A TODO comment cited LangChain’s output parsers as prior art, like citing a paper you’ve read but aren’t building on.
I named the project “Chain” anyway. Same metaphor. Deliberate.
Where it started
I was building a course curriculum tool, a system to generate and structure online course content using multiple LLM calls in sequence. Each call took a prompt, hit an API, and returned structured output. The plumbing for doing that was the same every time, so I pulled it out into a class. That class became Chain.
The first commit had Agent.py, Retriever.py, VectorStore.py, and a chains/ directory full of specific pipeline scripts: chain_curation.py, chain_RAG.py, chain_role_progression.py. It also had Course_Descriptions.py, which was pure domain data. So the very first version was half application, half framework.
The design decision that mattered most was also the first one: Jinja2 for prompt templating. The idea was that prompts are templates, not strings. You define them with `` placeholders, render them with context, and pass the result to the model. This made prompts inspectable and testable in a way that f-strings aren’t. You could version-control them meaningfully.
That decision never changed. It’s in Conduit today, 22 months later.
The framework was always load-bearing
Two weeks after the first commit, I’d built ask.py, a CLI tool for quick, one-off LLM queries. A few days later, obsidian.py, for summarizing YouTube videos and articles into vault notes. Both were built on Chain. From the start, it was the foundation for real tools I actually used.
In July, I added async batch processing. It worked well enough that I ran a large job and hit this:
“added a crude rate limit to Model.run_async because I accidentally sent 4,000 API calls”
That commit is dated July 14, 2024. It’s the most honest summary of what was happening: this wasn’t academic. It was sending actual API calls to actual endpoints, and when something went wrong the bill reflected it. The rate limit was crude (an asyncio.sleep() inserted between batches) but it worked.
v2: the lazy-load trigger
By October 2024, the project had accumulated enough cruft that startup time was visibly slow. The SDK imports — OpenAI, Anthropic, Google, Ollama, Groq — were all eager. Every invocation of ask.py waited two seconds before doing anything.
The fix was lazy loading: don’t import the SDK until the model is actually invoked. The commit that implemented it noted “saves two seconds on start up.” That seems minor, but when a tool is something you run dozens of times a day, two seconds is noise that wears on you.
That refactor triggered the v2 rewrite. Thirty-plus commits in a single day (October 21, 2024) restructured everything: setup.py, provider clients extracted into a clients/ directory, Pydantic Message objects replacing raw dicts, a MessageStore class for persistent conversation history. The rename commit (“retitled entire project to Chain”) landed at 00:50 that morning, which gives you some sense of how the session was going.
v2.5: it became a platform
By January 2025, Chain had a Chat class with a command system, an async ModelAsync subclass, SQLite caching, streaming, and a ReACT agent loop. On January 25, a commit read: “This is version 2.5; with Chat, CLI, and ReACT implementations.”
The more telling commit from the same week was this one, describing the new CLI base class:
“implementing a CLI class that will become the core of ask/leviathan/tutorize/cookbook”
Those were real tools I was building or planning. Chain had stopped being a framework I was developing in isolation and had become the infrastructure everything else ran on. The distinction matters: a library you’re prototyping can afford rough edges. A library that’s already running four different tools you use daily cannot.
v3: multimodal and distributed
Between June and July 2025, the project went from a text-only framework to a full multimodal platform. ImageMessage and AudioMessage joined TextMessage in a proper class hierarchy. Image generation landed (DALL-E, Gemini, HuggingFace). Text-to-speech across multiple providers. A ChainServer for remote model access over the local network.
There’s a cluster of chess-player-named machines in my homelab — magnus, petrosian, alphablue, caruana — each running Ollama. Chain had been tunneling to them via SSH since July 2024. The ChainServer formalized this: instead of SSH tunnels, you ran Chain as a server on one machine and called it remotely from another. The network had always been there; now the framework understood it.
The v3 milestone landed June 23, 2025. The commit message: “v3 is ready!”
The next day, work started on serialization, which turned out to take two weeks and prompted a commit message I won’t repeat here.
The rename
Chain was archived October 9, 2025. Not abandoned, just preserved. By then the project had 689 commits and was deeply entangled with a growing personal infrastructure stack: Siphon (a multimodal ingestion pipeline), Headwater (a local API server), and MCPLite (an MCP implementation that was built inside Chain, then extracted into its own project in April 2025).
Conduit, the successor, was already alive on September 29 — twelve days before the formal archive. The first commit said “Complete rewrite of conduit.”
It wasn’t a rewrite. The full Chain architecture carried over intact: all the client classes, the message hierarchy, the Chat and CLI layers, the cache, the multimodal support. The version number reset from 3.0.0 to 0.1.0 (later to 2.0.0). The package went from src/Chain/ to src/conduit/. That’s what the rename commit touched: setup.py and imports.
The “rewrite” was aspirational. The psychological clean slate was real. Sometimes you need to call something new to be willing to build it differently.
The actual redesign
The real architectural change happened in November and December 2025.
Chain’s model was stateful throughout: a Model object held provider configuration, a Chain object held the conversation, and methods on those objects drove execution. This worked fine until it didn’t — when you wanted to test a piece of it in isolation, or trace what happened when a tool call failed, the state made it hard.
The refactor I landed on was the “functional core, imperative shell” pattern. The Engine became a collection of static methods. Conduit and Model became mostly stateless. The execution loop — what happens when you send a message — became an explicit state machine driven by a ConversationState enum:
match conversation.state:
case ConversationState.GENERATE:
response = Engine.generate(request, model)
case ConversationState.EXECUTE:
conversation = Engine.execute(conversation, tools)
case ConversationState.TERMINATE:
break
That loop is readable. You can reason about it. You can test each case without constructing a full model object. Chain’s equivalent was scattered across methods and hard to follow.
A December 9 commit noted: “functional core, imperative shell pattern formalized.” A December 10 commit said: “in a deep dark forest where 2+2=5.” The two days were related.
Where it is now
Conduit is at 331 commits as of this writing, still active. The current architecture:
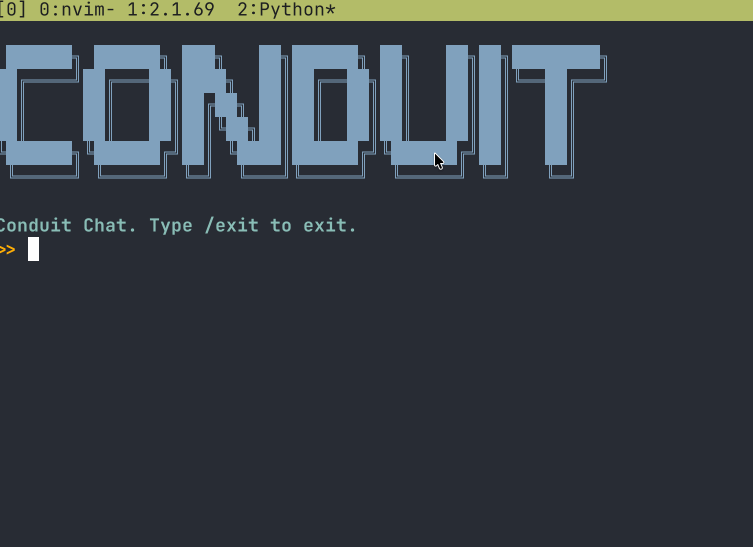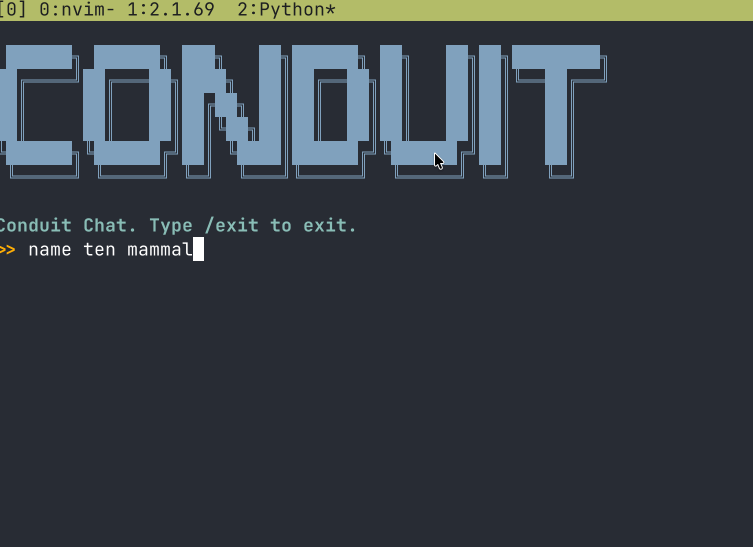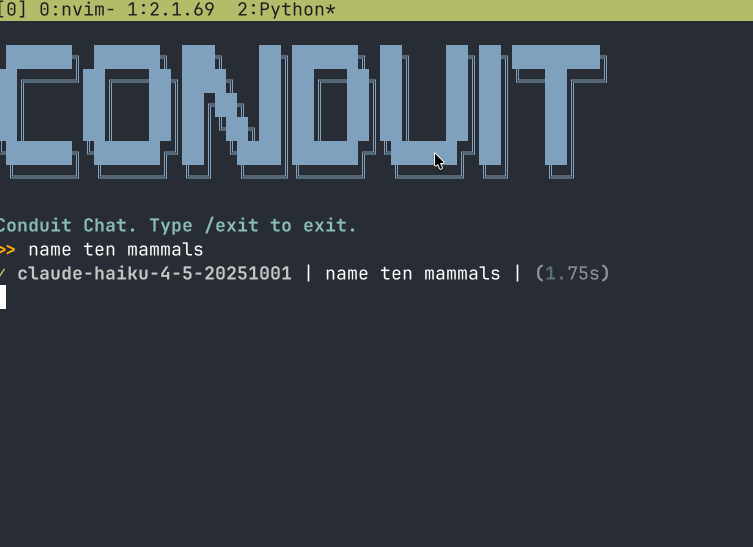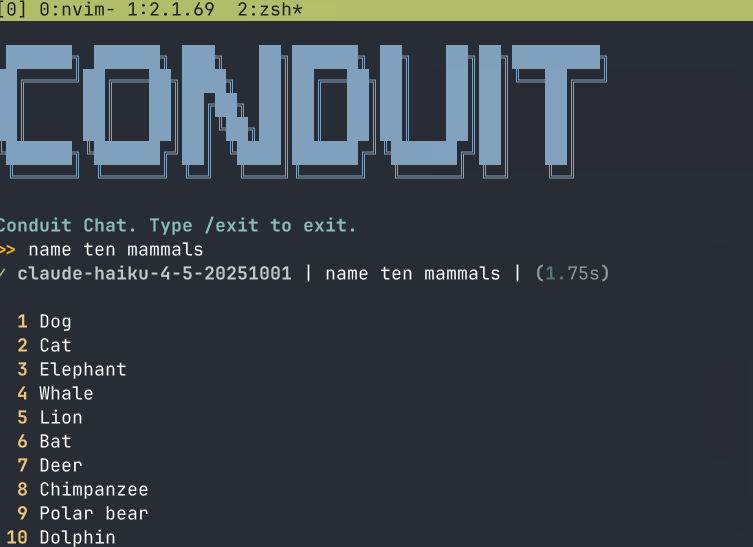
The chat UI, conduit chat, runs against any model in the registry. The command shown above is a terminal chat that supports tool calls, skills, streaming, and persistent conversation history via a DAG model (messages carry session_id and predecessor_id, so the conversation is a traversable graph rather than a linear list).
The provider list has expanded: Anthropic, Google, Ollama, Perplexity, Mistral, HuggingFace. OpenAI was removed entirely on February 28, 2026, in a commit with no explanation.
February also brought an eval framework: a golden dataset of summarization examples, a loss function, embeddings, and a Postgres-backed scoring pipeline. Using Conduit’s own workflow machinery to evaluate Conduit’s outputs feels like a milestone. It means the system is stable enough to trust with real work.
Why not LangChain
The honest answer is that I didn’t use LangChain because I started building before I fully understood what LangChain was, and by the time I understood it well enough to have an opinion, I already had something that did what I needed.
The more considered answer: LangChain’s reputation for complexity is not unearned. It’s a framework designed to be composable in ways that make every abstraction add another abstraction on top of it, until the stacktrace on a failure is fifteen frames deep and none of them are yours. What I needed was something I could read when it broke at 2am. That requirement is incompatible with most frameworks.
Every refactor in Chain’s history moved toward less code, not more. The instructor library replaced 75 lines of hand-rolled Pydantic parsing with three. Lazy loading removed two seconds by moving six import statements. The Engine refactor made the execution loop a single match statement instead of a tangle of object methods.
The framework that’s useful to me is the one I can hold in my head. Chain was 689 commits of learning what that actually means. Conduit is the version where I think I know.
Conduit is part of the Watershed ecosystem — a collection of personal AI infrastructure tools including Siphon (multimodal ingestion), Headwater (local LLM API server), and Watergun (tool server for Open WebUI). The Chain repository is archived at github.com/acesanderson-archive/Chain. Conduit is at github.com/acesanderson/conduit.